Can Use of Semantic Graph Improve Fake News Detection Accuracy?
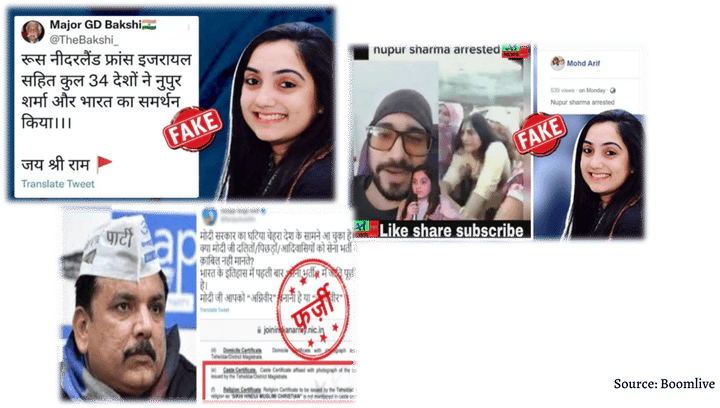
In our increasingly interconnected world, information flows at an unprecedented rate. Social media platforms have become the primary channels through which we receive and share news, connecting us with events as they unfold. However, this digital revolution has a dark side: the rampant proliferation of fake news. The deliberate distortion and fabrication of facts in fake news pose severe negative consequences for individuals and society, eroding trust in institutions and potentially inciting real-world harm. Recognizing the critical need to address this issue, researchers at the SoNAA (Social Network Analysis and Application) lab at the Indian Institute of Technology Jodhpur embarked on a journey to explore innovative methods for detecting fake news, with a particular focus on the power of semantic graph representations.
The challenge of fake news detection is multifaceted. Early approaches often relied on manually crafted textual features based on linguistic characteristics. These methods, while providing initial insights, were labor-intensive and limited in their ability to capture the nuanced semantic meaning embedded within news articles. Later, with the rise of deep learning, models utilizing LSTMs and RNNs emerged, demonstrating the ability to learn text features automatically. However, these sequence-based models often struggled to maintain longer text dependencies and were less effective at capturing complex semantic relations such as events, locations, and trigger words.
It was within this landscape of challenges and emerging possibilities that the SoNAA lab began to explore the use of Abstract Meaning Representation (AMR). AMR offered a unique advantage: it represents the logical structure of sentences using a graph-based formalism. By abstracting away from syntactic variations, AMR aims to capture the underlying semantic meaning of a sentence in a language-independent manner. The graph consists of nodes representing semantic concepts (entities, events, attributes) and edges representing the labeled relationships between them (e.g., agent, patient, time, location).
The researchers at SoNAA hypothesized that by leveraging the rich semantic information encoded in AMR graphs, they could develop more effective fake news detection models that could overcome the limitations of purely text-based or superficially knowledge-aware approaches. This led to the development of FakEDAMR (Fake News Detection using Abstract Meaning Representation Network)
Further to this research we began to investigate the potential of incorporating external knowledge to enhance fake news detection. Models like KAN and CompareNet explored the use of Wikidata as an external knowledge source to cross-reference factual claims. While these knowledge-aware approaches showed promise, they often faced challenges in reliably and efficiently integrating this external information. For instance, KAN primarily considered single-entity contexts, while CompareNet often selected only the first paragraph of an entity from Wikipedia, potentially missing crucial contextual links between entities. Other methods, like FinerFact, incorporated social information to assess news authenticity. However, social information can be manipulated, and these methods often relied on social diffusion and engagement patterns that can be challenging to capture accurately. We develop a model EA2N (Evidence-based AMR Attention Network) that efficiently incorporate external knowledge and take full advantage of AMR that shows promises in FakEDAMR model.
FakEDAMR: Focusing on the Semantic Backbone of Text (Gupta et al. 2023)
FakEDAMR, focused on leveraging the semantic features captured by the AMR graph itself, in combination with traditional textual features, to improve fake news detection. The core of FakEDAMR’s approach involved encoding the textual content of tweets using AMR graphs. For each tweet, an AMR graph was generated using the STOG model. To extract meaningful features from these graphs, FakEDAMR employed a process of RDF (Resource Description Framework) triplet extraction. The AMR graph was broken down into (subject, relation, object) triplets, which were then used to construct a new, simplified graph representing the core semantic relationships.
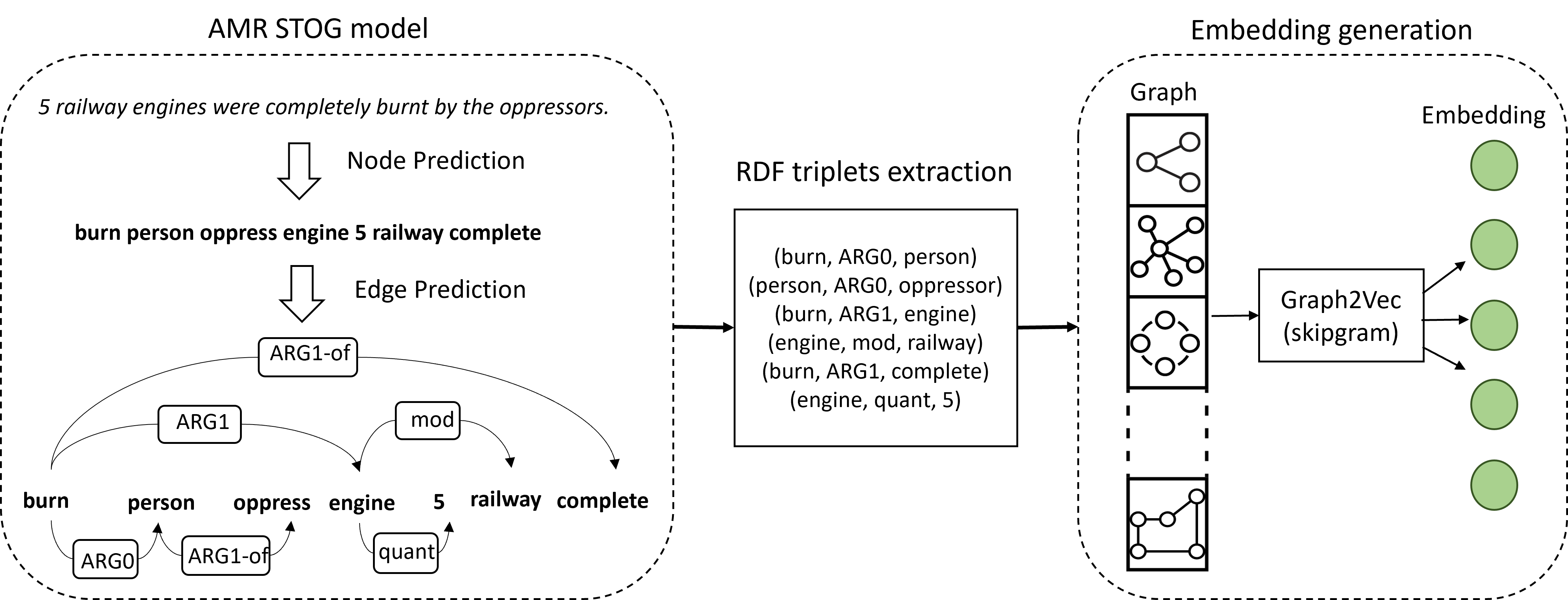
These constructed graphs were then fed into the Graph2Vec model, specifically the skip-gram variant, to obtain AMR graph embeddings. Graph2Vec learns vector representations of entire graphs, capturing their structural and relational information. FakEDAMR combined these AMR graph embeddings with syntactic and lexical features of the text. Two different sets of textual features were used:
- Feature-set 1: A collection of 37 handcrafted features encompassing morphological, vocabulary, and lexical aspects of the text.
- Feature-set 2: GloVe word embeddings pre-trained on a large Twitter corpus were used to represent the text.
The combined feature embeddings (textual + AMR graph embeddings) were then fed into a BiLSTM (Bidirectional Long Short-Term Memory) network for classification.
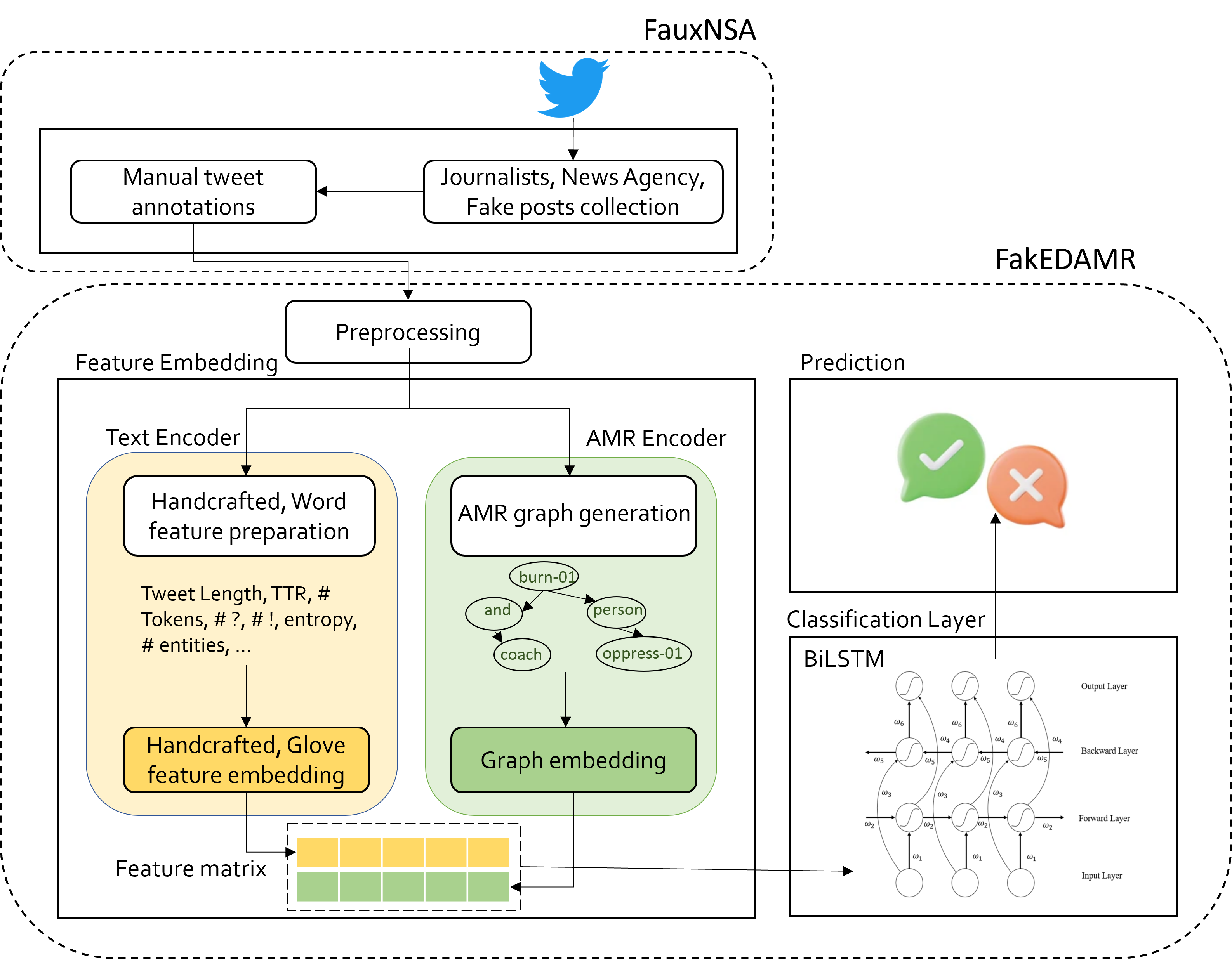
Methodology
To evaluate FakEDAMR, the SoNAA lab curated a new fake news dataset called FauxNSA, focusing on tweets related to the ‘Nupur Sharma’ and ‘Agniveer’ political controversies in India. This dataset, along with two publicly available datasets, Covid19-FND and KFN, was used for extensive experimentation.

The results consistently showed that adding AMR graph features significantly improved the performance of various machine learning and deep learning models across all datasets and both feature sets. For instance, BiLSTM with AMR-encoded Feature-set 2 achieved an accuracy of 93.96% and an F1-score of 91.96% on the FauxNSA dataset, outperforming the same BiLSTM model using only textual features. Similar improvements were observed on the Covid19-FND and KFN datasets.
Ablation studies using visualization techniques further demonstrated that AMR features helped the model to create a clearer separation boundary between real and fake news samples, indicating that the semantic information captured by AMR was indeed valuable for the classification task.
EA$^2$N: Bridging the Gap with External Knowledge-Enhanced Semantic Graphs (Gupta et al. 2025)
While the FakEDAMR uses semantic graphs, EA$^2$N extend this model by effectively incorporating external knowledge. The core idea behind EA$^2$N was to enrich the semantic representation provided by AMR with evidence extracted from external knowledge sources, specifically Wikidata in this case. This led to the introduction of a novel graph structure called WikiAMR.
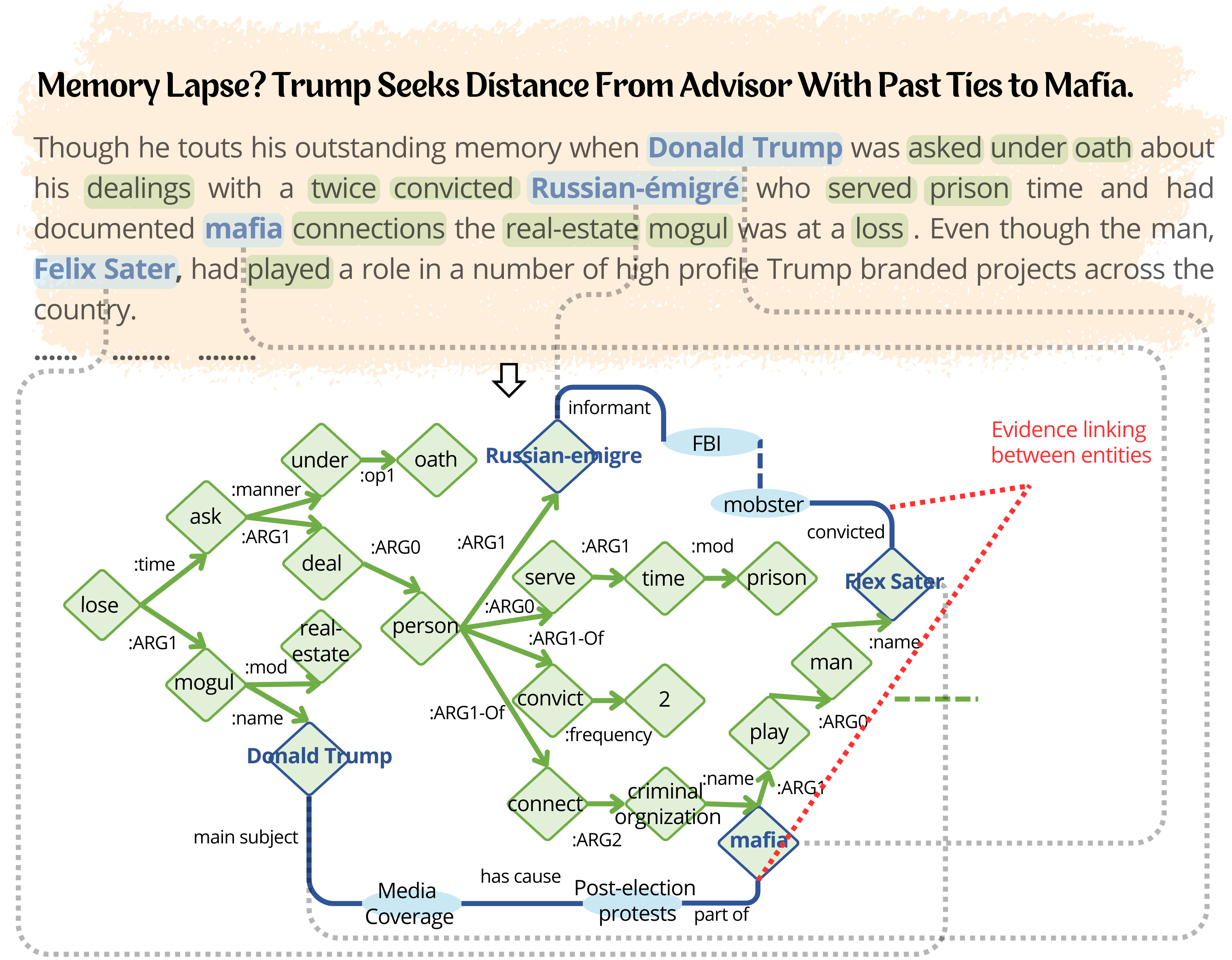
Illustration of WikiAMR
The creation of WikiAMR involved an evidence-linking algorithm that connected entities within the base AMR graph (derived from the news article’s text) with relevant information from Wikidata. This algorithm employed two key filtering steps:
- Entity-Level Filtering (ELF): This step assessed the relevance between pairs of entities within the AMR graph by examining their corresponding representations in Wikidata. A relatedness score was calculated using the TagMe API, and if this score exceeded a predefined threshold ($\gamma$), the entities were considered potentially related in Wikidata. This indicated the possibility of an evidence path existing between them.
- Context-Level Filtering (CLF): Once a potential link between two entities was identified through ELF, the CLF algorithm searched for an evidence path connecting them within the Wikidata knowledge graph. For each entity along this path, the algorithm calculated a relevance score based on its connection to the destination entity, taking into account the path’s length (number of hops). If this score exceeded another threshold ($\delta$), the entity was considered part of a relevant evidence path.
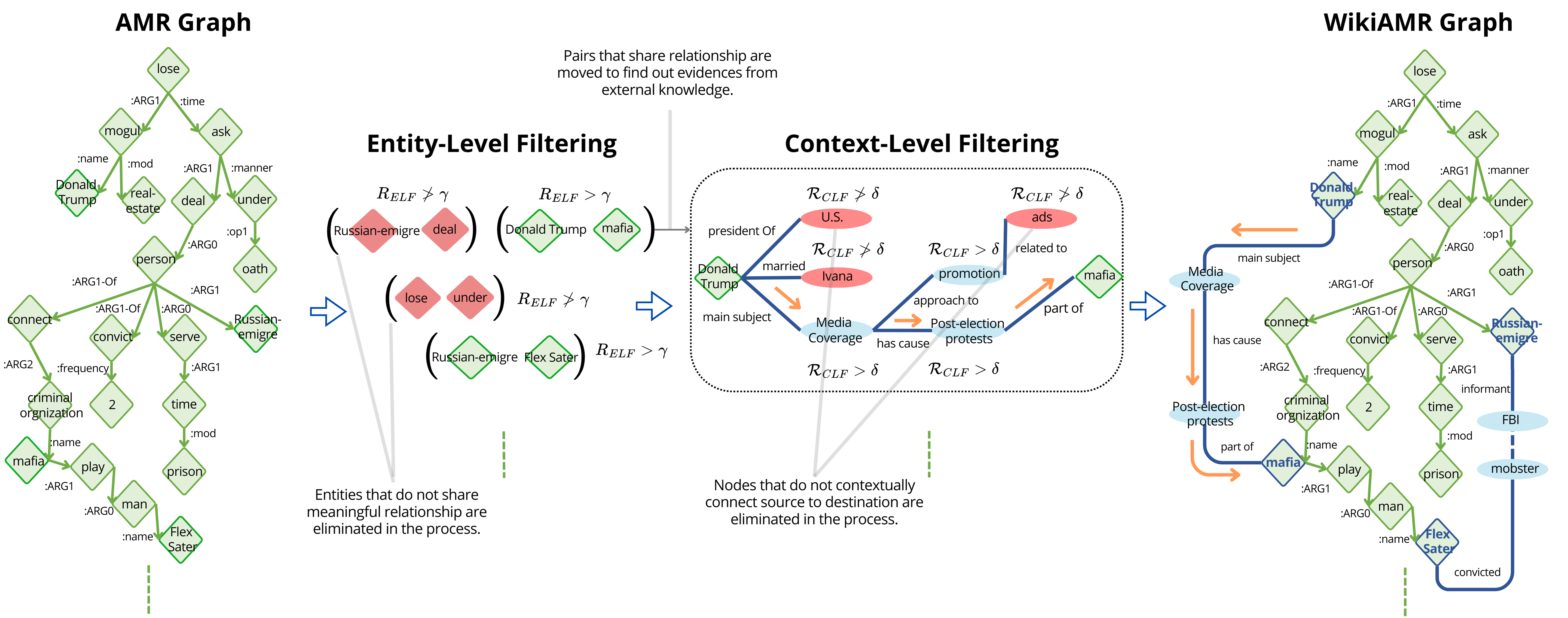
Illustration of WikiAMR construction using ELF and CLF
Through this evidence-linking process, EA$^2$N effectively integrated undirected evidence paths from Wikidata into the directed acyclic structure of the base AMR graph, forming the WikiAMR graph. Figure above provides a example illustration of an WikiAMR, showing how entities like ‘Donald Trump’ and ‘Mafia’ could be linked through intermediary nodes representing ‘Media Coverage’ and ‘Post-election protest’ with specific semantic relations.
Similarly, a path was established between ‘Russian-emigre’ and ‘Flex Ster’. These evidence paths provided valuable context and factual information to assess the credibility of the news content.
To effectively learn from these enriched WikiAMR graphs, the EA$^2$N framework incorporated a Graph Encoder module. This module utilized a path-aware graph learning module that employed a modified Graph Transformer to capture crucial semantic relationships among entities over the evidence paths. A Relation Path Encoder was designed to encode the shortest paths between entities in the WikiAMR graph using GRU-based RNNs. The attention mechanism within the Graph Transformer then computed attention scores based on both the entity representations and their relation representations, allowing the model to reason over the intricate relationships within the WikiAMR graph.
In parallel, EA$^2$N also included a Language Encoder module that used the ELECTRA pre-trained language model to encode the textual content of the news article. Furthermore, affective lexical features were extracted and integrated to enhance the language encoder’s ability to discern subtle emotional and sentiment cues in the text.

Overall architecture of EA$^2$N
Finally, a Classification Module concatenated the representations from the Graph Encoder (WikiAMR) and the Language Encoder and fed them into a classification transformer followed by a softmax layer to predict the veracity of the news article.
Extensive experiments on the Politifact and Gossipcop datasets demonstrated the superior performance of EA$^2$N compared to state-of-the-art methodologies, achieving a 2-3% improvement in F1-score and accuracy. Notably, this improvement was achieved without relying on social information, which many other high-performing models utilized. The ablation studies further highlighted the significant contribution of the WikiAMR graph, showing a 3-4% performance enhancement when evidence was integrated into the base AMR graph. Statistical t-tests confirmed that these improvements were statistically significant.
The Power of Semantic Graphs: A Shared Insight
Both EA$^2$N and FakEDAMR, developed in our lab, converged on a crucial finding: leveraging the semantic information captured by graph representations significantly enhances the accuracy of fake news detection. While EA$^2$N focused on enriching this semantic representation with external, factual knowledge, FakEDAMR demonstrated the intrinsic value of the AMR graph structure itself in improving classification performance when combined with traditional textual features.
The main contribution of this work lies in highlighting how graph representation learning can overcome the limitations of purely sequence-based models in capturing complex semantic relationships and incorporating external knowledge in a more structured and effective manner for fake news detection.
- Capturing Complex Semantics: AMR graphs inherently represent the relationships between entities, events, and attributes in a sentence, going beyond the linear structure of text. This allows the models to understand “who did what to whom, when, and where” more effectively, which is crucial for discerning subtle manipulations and fabricated connections in fake news.
- Integrating External Knowledge Robustly: EA$^2$N’s WikiAMR approach demonstrated a novel and effective way to integrate external knowledge from Wikidata. By explicitly linking entities in the AMR graph to relevant evidence paths in Wikidata, the model could directly reason over factual claims and identify inconsistencies. This method is more reliable than simply incorporating entity descriptions, as it captures the relationships between entities and the evidence supporting or refuting those relationships.
- Improved Performance: The consistent improvements in F1-score and accuracy achieved by both FakEDAMR and EA$^2$N across various datasets and compared to state-of-the-art baselines underscore the effectiveness of the graph-based approaches. These results highlight the potential of semantic graph representations to push the boundaries of fake news detection accuracy.
- Explainability (in EA$^2$N): The paper on EA$^2$N also points out that the knowledge-based approach inherent in WikiAMR offers a degree of explainability, as the model can potentially reference specific pieces of validated information from Wikidata to support its classification decisions. This could increase user trust in fact-checking systems.
Looking Ahead: The Future of Semantic Graphs in Fake News Detection and Beyond
The work of the SoNAA lab has not only provided valuable insights into the effectiveness of semantic graphs for fake news detection but has also opened up avenues for future research and applications.
Future directions could include:
- Exploring other knowledge graphs: While Wikidata proved to be a valuable resource, investigating the use of other domain-specific knowledge graphs could further enhance the performance and applicability of models like EA$^2$N.
- Integrating pre-trained language models with AMR more deeply: FakEDAMR’s initial approach of combining AMR embeddings with textual embeddings could be extended by exploring more sophisticated ways to fuse these representations, potentially even incorporating pre-trained transformer models directly into the AMR encoding process.
- Addressing limitations in AMR graph construction: The error case analysis in the EA$^2$N paper highlighted the impact of incomplete AMR graph construction on model accuracy. Future work could focus on improving the robustness and completeness of AMR parsers, particularly for noisy social media text.
- Extending the approach to other NLP tasks: The concept of WikiAMR is not limited to fake news detection and could be applied to other NLP tasks where external knowledge-enhanced semantic understanding is beneficial, such as law enforcement and insurance validation.
In conclusion, the research conducted by us on EA$^2$N and FakEDAMR provides compelling evidence that the use of semantic graph representations, particularly Abstract Meaning Representation (AMR), holds significant potential for improving the accuracy of fake news detection. By effectively capturing complex semantic relationships and, in the case of EA$^2$N, integrating external knowledge in a structured manner, these models have demonstrated superior performance compared to existing state-of-the-art approaches. These works points out the power of graph representation learning in tackling the critical challenge of online misinformation and paves the way for future advancements in this crucial field. The answer to the question “Can use of semantic graph improve fake news detection accuracy?” is a resounding yes, as demonstrated by the innovative work emanating from the SoNAA lab.