Cyberbully: Aggressive Tweets, Bully and Bully Target Profiling from Multilingual Indian Tweets
Social media has given us incredible power to connect, share, and express ourselves. However, this freedom also has a darker side: the rise of online harassment and cyberbullying. Hurtful messages, aggressive comments, and targeted abuse can have a significant emotional and psychological impact on individuals. While platforms like Twitter offer reporting mechanisms, these often take time, making them less effective in immediate situations.
Recognizing this critical issue, our paper titled “Cyberbully: Aggressive Tweets, Bully and Bully Target Profiling from Multilingual Indian Tweets” presents an innovative approach to automatically detect cyberbullying in the diverse linguistic landscape of Indian Twitter. This blog post will break down this research in an easy-to-understand way, exploring how this study tackles the challenge of online aggression in multiple languages.
The Challenge: Cyberbullying in a Land of Many Languages
Imagine trying to build a system that can understand and identify aggressive content online. Now, add the complexity of dealing with multiple languages! India is a melting pot of languages, and its social media reflects this diversity, with users expressing themselves in Hindi, English, Bengali, Hinglish (Hindi written in Roman script), and many more.
Most previous research on automatically detecting online aggression has primarily focused on English. When it comes to handling multiple languages, existing methods often involve either translating everything to English or creating separate detection systems for each language. These approaches can have limitations, such as loss of nuances during translation or the need for extensive resources to build individual models for every language. This is where this research steps in with a more streamlined and efficient solution.
An End-to-End Multilingual System
This study proposes an end-to-end system designed to identify potential bullies and their targets from aggressive tweets in several Indian languages. The beauty of this system lies in its ability to first determine the language of a tweet and then use a specific aggression detection model trained for that particular language. This eliminates the need for translation and allows for more accurate detection by considering language-specific nuances and slang.
Let’s take a closer look at how this system works, as illustrated in

The process can be broken down into the following key steps:
- Data Collection: We gathered a large dataset of over 150,000 tweets in Hindi, English, Bengali, and Hinglish. This data is crucial for training the system to recognize different languages and identify aggressive content within them.
- Language Detection: When a new tweet comes in, the system first uses a language detection model to automatically identify which of the four languages it is written in. This model was trained on data from sources like Wikipedia and a specific Hinglish dataset. The following figure shows examples of the data used for language detection.

-
Aggression Detection: Once the language is identified, the tweet is passed on to a language-specific aggression detection model. This means there’s a dedicated model for English aggression, another for Hindi, and so on. These models are trained to identify aggressive content based on patterns and features specific to each language. Figure shows examples of the data used for training these aggression detection models, which included labeling tweets as Aggressive or Non-Aggressive.

-
LSTM Classifiers: The core of both the language detection and aggression detection models are LSTM (Long Short-Term Memory) based classifiers. LSTM is a type of neural network particularly good at understanding sequences of data, like words in a sentence. It has a “memory cell” that helps it retain important information and discard irrelevant parts of the text, allowing it to learn long-range dependencies in language. Each LSTM unit uses “gates” to control what information is kept or forgotten. These models are trained to minimize errors in their predictions.
Finding the Bullies and Their Targets
After successfully detecting aggressive tweets, we experimented to identify potential bullies and their targets as shown in the following Figure.

Different steps are explained below:
- Identifying Potential Bullies: If a tweet is classified as aggressive, the system retrieves a sample of the author’s recent tweets (around 100). If a certain percentage (defined by the researchers) of these recent tweets are also aggressive, the user is flagged as a potential bully. This helps to differentiate between a single aggressive outburst and a pattern of bullying behavior.
- Identifying Potential Targets: Within each aggressive tweet, the system looks for user mentions (using the “@” symbol). The users mentioned in aggressive tweets are then considered potential targets.
Uncovering Patterns: Insights into Bullies and Targets
We also analyzed Twitter profiles of these users to find potential patterns. By examining factors like follower count, friends count (number of accounts they follow), and tweet frequency, we uncovered some interesting trends, visualized as:
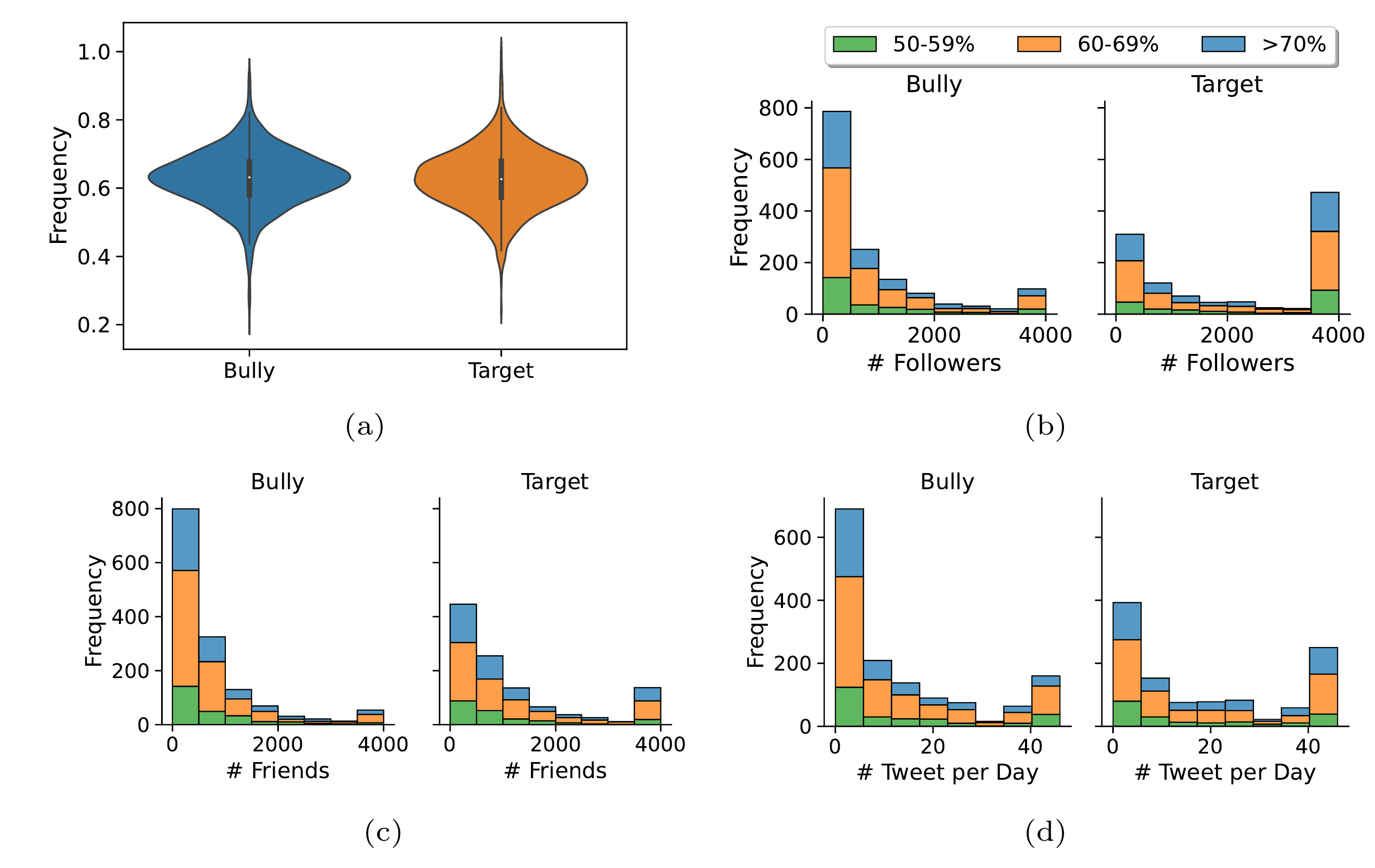
Here are some key observations:
- Bullies:
- A significant number of suspected bullies post a high percentage (60% or more) of aggressive tweets.
- Many bullies have a lower number of followers (below 500), although there’s also a notable group with over 4000 followers.
- Similarly, most bullies follow fewer than 1000 people, particularly less than 500.
- The majority of suspected bullies tweet between 0 to 10 times per day, but some tweet much more frequently (60-80 times a day).
- Targets:
- Interestingly, many of the users identified as targets of aggressive tweets also post aggressive tweets themselves. This suggests that the line between bully and victim might not always be clear-cut.
- There are more target users with a high follower count (greater than 4000) compared to bullies. This could indicate that celebrities or individuals with a large online presence are more likely to be targeted.
These findings highlight the complex nature of online aggression and suggest that simply classifying a tweet as aggressive isn’t enough; understanding the broader behavior and profile of users involved is crucial.
How Well Did the System Perform?
The results of the experimental evaluation is shown in Table 1:
Table 1: Precision, Recall and F1 score for aggression detection.
| Language | Precision | Recall | F1 Score |
|---|---|---|---|
| English | 0.7255 | 0.7382 | 0.7318 |
| Hindi | 0.8427 | 0.8255 | 0.8341 |
| Bengali | 0.8125 | 0.6046 | 0.6933 |
| Hinglish | 0.8735 | 0.9512 | 0.9107 |
As you can see, the system achieved good F1 scores across all four languages, particularly excelling in Hinglish and Hindi. The language detection model also demonstrated very high accuracy (99.97%) in identifying the correct language of a tweet.
Conclusion
This research provides a significant step forward in tackling the challenge of cyberbullying in multilingual online environments like Indian Twitter. By developing an end-to-end system that understands different languages and identifies patterns in user behavior, this study offers valuable insights for building more effective tools to combat online harassment.